
A teoria das probabilidades
Você sabia ...
SOS acredita que a educação dá uma chance melhor na vida de crianças no mundo em desenvolvimento também. Com SOS Children você pode escolher para patrocinar crianças em mais de cem países
A teoria das probabilidades é o ramo da matemática em causa com a análise de fenômenos aleatórios. Os objetos centrais da teoria das probabilidades são variáveis aleatórias , processos estocásticos, e eventos: abstrações matemáticas de eventos não-deterministas ou quantidades medidas que podem ser tanto ocorrências únicas ou evoluem ao longo do tempo de uma forma aparentemente aleatória. Apesar de uma moeda indivíduo lance ou o rolo de um dado é um evento aleatório, se repetida muitas vezes a seqüência de eventos aleatórios irá exibir determinados padrões estatísticos, que podem ser estudadas e previstos. Dois resultados representativos matemáticas que descrevem esses padrões são o lei dos grandes números ea teorema do limite central.
Como uma base matemática para as estatísticas , teoria da probabilidade é essencial para muitas atividades humanas que envolvem a análise quantitativa de grandes conjuntos de dados. Métodos da teoria das probabilidades também se aplicam à descrição de sistemas complexos dadas apenas um conhecimento parcial de seu estado, como em mecânica estatística . A grande descoberta de século XX física era a natureza probabilística de fenômenos físicos em escalas atômicas, descritas na mecânica quântica .
História
A teoria matemática da probabilidade tem suas raízes em tentativas de analisar jogos de azar por Gerolamo Cardano, no século XVI, e por Pierre de Fermat e Blaise Pascal , no século XVII (por exemplo, o " problema dos pontos ").
Inicialmente, a teoria da probabilidade considerado principalmente eventos discretos, e seus métodos eram principalmente combinatória . Eventualmente, analíticos considerações compelido a incorporação de variáveis contínuas na teoria. Isso culminou na teoria da probabilidade moderna, as fundações de que foram colocadas por Andrey Nikolaevich Kolmogorov. Kolmogorov combinado a noção de espaço amostral, introduzido pela Richard von Mises, e teoria da medida e apresentou a sua sistema de axiomas para a teoria da probabilidade, em 1933. Rapidamente este tornou-se o indiscutível base axiomática para a teoria da probabilidade moderna.
Tratamento
A maioria das introduções à teoria da probabilidade tratar distribuições de probabilidade discretas e distribuições de probabilidade contínuas separadamente. O tratamento baseia a teoria da medida mais matematicamente avançado de probabilidade abrange tanto o discreto, o contínuo, qualquer mistura dos dois e muito mais.
Distribuições de probabilidade discretas
Teoria da probabilidade discreta lida com eventos que ocorrem em espaços amostrais contábeis.
Exemplos: Arremesso de dados , experiências com baralhos de cartas , e passeio aleatório.
Definição clássica: Inicialmente, a probabilidade de que um evento ocorra foi definida como o número de casos favoráveis para o evento, sobre o número total de resultados possíveis em um espaço de amostra equiprovável.
Por exemplo, se o evento é "a ocorrência de um número mesmo quando uma matriz é enrolado ", a probabilidade é dada pela  , Uma vez que três rostos dos 6 têm até mesmo números e cada face tem a mesma probabilidade de aparecer.
, Uma vez que três rostos dos 6 têm até mesmo números e cada face tem a mesma probabilidade de aparecer.
Definição moderna: A definição moderna começa com um conjunto chamado de espaço amostral, que se refere ao conjunto de todos os resultados possíveis no sentido clássico, denotado por  . Em seguida, é assumido que, para cada elemento
. Em seguida, é assumido que, para cada elemento  , Um valor intrínseco "probabilidade"
, Um valor intrínseco "probabilidade" 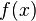 está ligado, o que satisfaz as seguintes propriedades:
está ligado, o que satisfaz as seguintes propriedades:
![f (x) \ in [0,1] \ mbox {para todo} x \ in \ Omega \ ,;](../../images/493/49335.png)

Isto é, a função de probabilidade f (x) encontra-se entre zero e um para cada valor de x no espaço Ω amostra, e a soma de f (x) ao longo de todos os valores de x no espaço Ω amostra é exactamente igual a 1. Um evento é definido como qualquer subconjunto 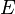 do espaço de amostragem
do espaço de amostragem 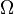 . A probabilidade do evento definido como
. A probabilidade do evento definido como

Assim, a probabilidade de todo o espaço da amostra é de 1, e a probabilidade do evento nulo é 0.
A função o mapeamento de um ponto no espaço de amostragem para o valor "probabilidade" é chamado um função massa de probabilidade abreviado como pmf. A definição moderna não tenta responder como funções de massa de probabilidade são obtidas; em vez disso, constrói uma teoria que assume sua existência.
Distribuições de probabilidades contínuas
Teoria da probabilidade contínua lida com eventos que ocorrem em um espaço contínuo amostra.
Definição clássica: A definição clássica divide quando confrontado com o caso contínuo. Ver Paradoxo de Bertrand.
Definição moderna: Se o espaço amostral é os números reais (  ), Em seguida, uma função de chamada do função de distribuição cumulativa (ou cdf)
), Em seguida, uma função de chamada do função de distribuição cumulativa (ou cdf) 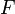 assume-se que existem, que dá
assume-se que existem, que dá 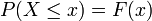 para uma variável aleatória X. Isto é, F (x) devolve a probabilidade de que X será menor do que ou igual a x.
para uma variável aleatória X. Isto é, F (x) devolve a probabilidade de que X será menor do que ou igual a x.
O cdf deve satisfazer as seguintes propriedades.
- é um monotonicamente não decrescente, função direita contínua;
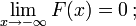
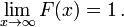
Se é diferenciável, então a variável aleatória X é dito ter uma função densidade de probabilidade ou pdf ou simplesmente densidade 
Para um conjunto  , A probabilidade da variável aleatória X sendo em é definido como
, A probabilidade da variável aleatória X sendo em é definido como

No caso de a função de densidade de probabilidade existe, isto pode ser escrito como

Considerando que existe o pdf somente para variáveis aleatórias contínuas, existe a cdf para todas as variáveis aleatórias (incluindo variáveis aleatórias discretas) que levam em valores 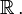
Estes conceitos podem ser generalizados para casos multidimensionais sobre 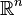 e outros espaços amostrais contínuos.
e outros espaços amostrais contínuos.
Teoria da probabilidade Medida teórica
A raison d'être do tratamento medida da teoria da probabilidade é que ele unifica o discreto eo contínuo, e faz a diferença uma questão de qual medida é usada. Além disso, abrange distribuições que não são nem misturas discretas nem contínuas, nem dos dois.
Um exemplo de tais distribuições pode ser uma mistura de distribuições discretas e contínuas, por exemplo, uma variável aleatória, que é 0, com uma probabilidade de 1/2, e tem um valor de distribuição aleatória normal com probabilidade 1/2. Pode ainda ser estudado, em certa medida, considerando-se ter uma PDF de ![(\ Delta [x] + \ varphi (x)) / 2](../../images/493/49348.png) , Onde
, Onde ![\ Delta [x]](../../images/493/49349.png) é o Função delta de Kronecker.
é o Função delta de Kronecker.
Outras distribuições não pode mesmo ser uma mistura, por exemplo, o Distribuição Cantor não tem probabilidade positiva para qualquer ponto único, nem tem uma densidade. A abordagem moderna à teoria da probabilidade resolve esses problemas usando teoria da medida para definir o espaço de probabilidade :
Dado qualquer conjunto  , (Também chamado espaço de amostra) e uma σ-álgebra
, (Também chamado espaço de amostra) e uma σ-álgebra 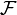 sobre ela, uma medir
sobre ela, uma medir 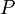 é chamado de uma medida de probabilidade se
é chamado de uma medida de probabilidade se
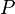 é não-negativa;
é não-negativa; 
Se é um Borel σ-álgebra, então há uma única medida de probabilidade em para qualquer CDF, e vice-versa. A medida correspondente a um CDF é dito para ser induzido pelo CDF. Esta medida coincide com a pmf para variáveis discretas, e pdf para variáveis contínuas, tornando a abordagem teórica medida livre de falácias.
A probabilidade de um conjunto no σ-álgebra é definido como
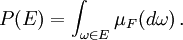
em que a integração é em relação à medida 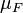 induzida pela
induzida pela 
Além de fornecer uma melhor compreensão e unificação de probabilidades discretas e contínuas, o tratamento medida de teoria também nos permite trabalhar em probabilidades fora , Como na teoria de processos estocásticos. Por exemplo, para estudar Movimento Browniano, a probabilidade é definida em um espaço de funções.
Distribuições de probabilidades
Certas variáveis aleatórias ocorrem frequentemente em teoria da probabilidade, porque eles também descrevem muitos processos naturais ou físicas. Suas distribuições, portanto, ganharam importância especial na teoria da probabilidade. Algumas distribuições discretas fundamentais são a discreta uniforme, Bernoulli, binomial , binomial negativa, de Poisson e distribuições geométricas. Distribuições contínuas importantes incluem o uniforme contínuo, normais , exponencial , gama e distribuições beta.
Convergência de variáveis aleatórias
Em teoria da probabilidade, existem várias noções de convergência para variáveis aleatórias . Eles estão listados abaixo em ordem de força, ou seja, qualquer noção de convergência subsequente na lista implica convergência de acordo com todas as noções precedentes.
- Convergência em distribuição: Como o nome indica, uma sequência de variáveis aleatórias
 converge para a variável aleatória
converge para a variável aleatória 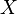 na distribuição, se as respectivas funções de distribuição cumulativas
na distribuição, se as respectivas funções de distribuição cumulativas 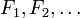 convergem para a função de distribuição cumulativa de , Onde é contínua.
convergem para a função de distribuição cumulativa de , Onde é contínua.
- Notação comum mais curto mão:

- Notação comum mais curto mão:
- Convergência fraco: A seqüência de variáveis aleatórias
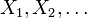 Diz a convergir para a variável aleatória fracamente se
Diz a convergir para a variável aleatória fracamente se 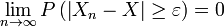 para cada Convergência fraca ε> 0. também é chamado de convergência em probabilidade.
para cada Convergência fraca ε> 0. também é chamado de convergência em probabilidade.
- Notação comum mais curto mão:
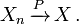
- Notação comum mais curto mão:
- Forte convergência: A seqüência de variáveis aleatórias Diz a convergir para a variável aleatória fortemente se
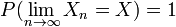 . Convergência forte também é conhecido como convergência quase certa.
. Convergência forte também é conhecido como convergência quase certa.
- Notação comum mais curto mão:

- Notação comum mais curto mão:
Intuitivamente, a convergência forte é uma versão mais forte da convergência fraca, e em ambos os casos, as variáveis aleatórias mostram uma correlação com o aumento . No entanto, em caso de convergência na distribuição, os valores realizados das variáveis aleatórias não precisam convergir, e qualquer possível correlação entre eles é irrelevante.
Lei dos grandes números
Intuição comum sugere que se uma moeda honesta é jogado muitas vezes, em seguida, cerca de metade do tempo que irá transformar-se cabeças, ea outra metade vai virar-se caudas. Além disso, o mais frequentemente a moeda é lançada, o mais provável é que ele deve ser a relação entre o número de cabeças para o número de caudas irá aproximar a unidade. Probabilidade moderna fornece uma versão formal desta idéia intuitiva, conhecida como a lei dos grandes números. Esta lei é notável porque em nenhum lugar é assumido nos fundamentos da teoria da probabilidade, mas sim emerge dessas fundações como um teorema. Desde que liga probabilidades teoricamente derivadas de sua freqüência real de ocorrência no mundo real, a lei dos grandes números é considerado como um dos pilares da história da teoria estatística.
A lei dos grandes números (LLN) afirma que a média da amostra 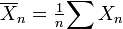 de (Independentes e identicamente distribuídos variáveis aleatórias com expectativa finita
de (Independentes e identicamente distribuídos variáveis aleatórias com expectativa finita 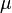 ) Converge para a expectativa teórica
) Converge para a expectativa teórica 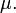
É nas diferentes formas de Convergência de variáveis aleatórias que separa o fraco eo forte lei dos grandes números
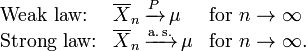
Resulta do que LLN se um evento de probabilidade p é observado repetidamente durante as experiências independentes, a razão entre a frequência observada de evento para que o número total de repetições converge para p.
Colocando isto em termos de variáveis aleatórias e LLN dispomos 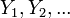 são independentes Variáveis aleatórias de Bernoulli que tomam valores com uma probabilidade p e 0 com probabilidade 1- p.
são independentes Variáveis aleatórias de Bernoulli que tomam valores com uma probabilidade p e 0 com probabilidade 1- p.  Por tudo que eu e resulta do que LLN
Por tudo que eu e resulta do que LLN 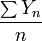 converge para p quase certamente.
converge para p quase certamente.
Teorema do limite Central
O teorema do limite central explica a ocorrência ubíqua da distribuição normal na natureza; é um dos teoremas mais célebres da probabilidade e estatística.
O teorema indica que a média de muitas variáveis aleatórias independentes e identicamente distribuídas com variância finita tende a uma distribuição normal , independentemente da distribuição seguido pelas variáveis aleatórias originais. Formalmente, deixe- variáveis aleatórias independentes com média 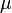 e variância
e variância 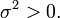 Em seguida, a sequência de variáveis aleatórias
Em seguida, a sequência de variáveis aleatórias
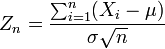
converge em distribuição para a normal padrão variável aleatória.